アンケート分析Proのご紹介
アンケート分析Pro
数値との相関一瞥機能や、追加調査を手軽に行う「ツイ追」機能を装備し、ハイエンドの分析官のひらめきを支援
1. 背景
ビッグデータの時代といわれ、大量のデータ、顧客の声、ソーシャルメディアの書き込みを分析してビジネスの舵取り、改善をすべきとされながら、現状は未だ上流の『収集』『蓄積』にとどまり、最重要の『分析』にまで手が回らないようです。これではビッグデータの利活用で得られる高付加価値の知見をみすみす逃すことになってしまいます。
また、従来、ビッグデータは数値データとテキストデータの2種に分断されており、それぞれについてデータマイニングのツールと、テキストマイニングのツールを別々に使う必要がありました。これらを同時に、相関関係をみながら絞り込んで、同じツール上で分析を進めていくことは困難でした。
メタデータ社では、従来から、文脈を反映した高精度ネガポジAPI、感情解析APIの出力数値や、5W1H抽出API により日付時刻、場所、個人名、法人名、イベント名、製品名等を正規化した結果を提供。ハイエンド顧客の要求に応える高い精度で、テキストビッグデータを分析可能にする技術を提供してまいりました。マーケティングや、具体的に営業トーク原稿の改善(顧客アンケート結果から顧客の「心に刺さる」フレーズを発見して)などのために、高精度にテキストを分析、ランキングする技術を磨いてまいりました。


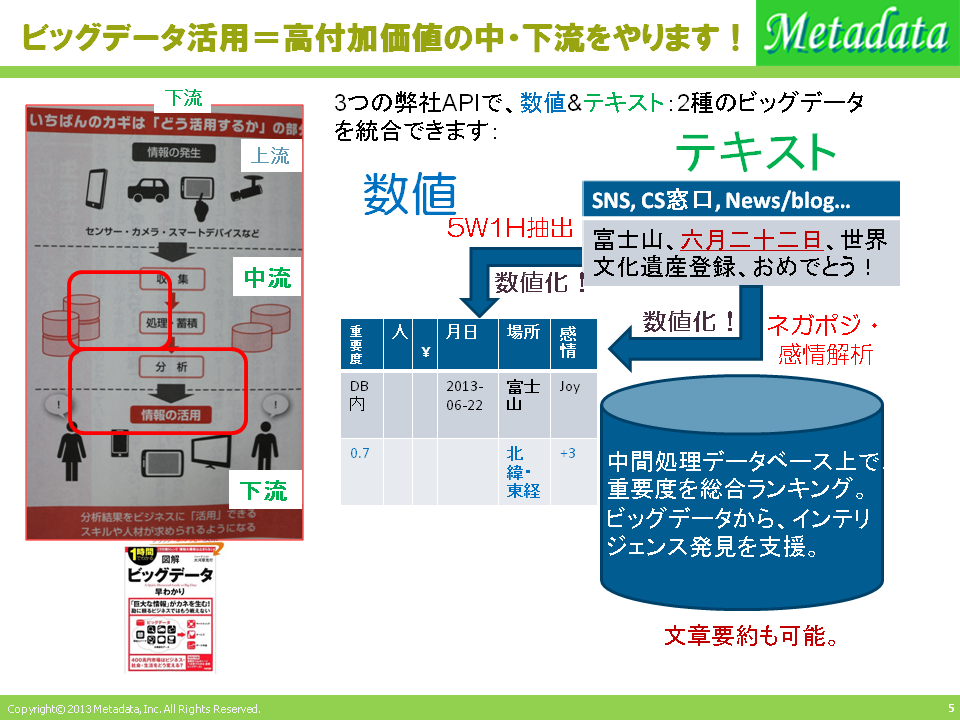
2. アンケート分析Proにより同一データベース上で自由回答を統合評価
今回、SaaSでご提供するアンケート分析Proでは、アンケート回答者の選択回答、記入数値、評価者の選択、そして自由回答を高精度ネガポジAPIで解析した「-3」から「+3」までの数値、そして自由回答本文をベクトル数値に分解した結果を全て同一のデータベース上に保持しています。このため、これらの値に対する条件を任意に組み合わせて、回答群を絞り込むことが可能です。言葉の係り受けランキングから主要テーマを発掘することもできます(下図左下)。
以下の機能を含め、発想の種の宝庫である自由回答を中心に、アンケート・データベースと分析官が「対話」し、定量評価はもちろん、新たなテーマや知見、応用素材を次々と発掘できるワークベンチとして、アンケート分析Proは、機能します。

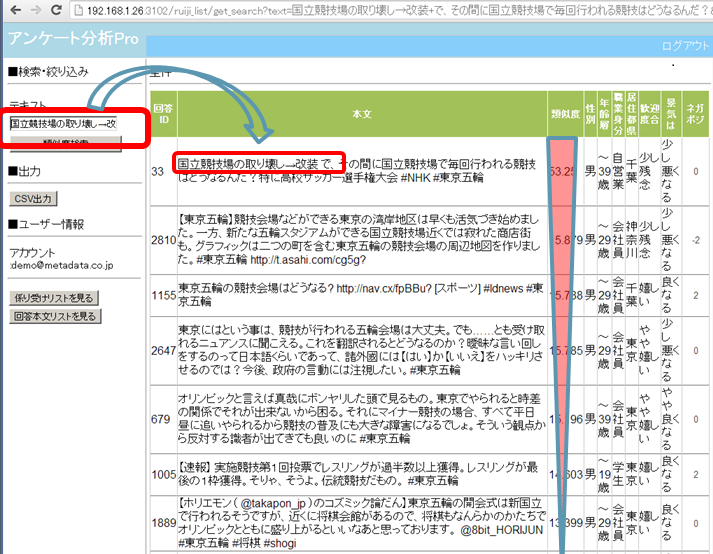
3. フルテキスト類似検索で素早く疑問に回答。仮説を検証。
イントラネット検索エンジンの先駆け、ジャストシステムのConceptBase(TM)以来、全自動で社内文書をインデクシング、検索可能にするGoogle Appliance(TM)など、外付け(add-on)の仕組みとして、高速で、程よく網羅的で体感精度の高い検索機能が提供されてきました。アンケート分析Proでは、このフルテキスト類似検索と同等の機能を、データベースエンジン上に実現。自然文テキストを投入すると、自動的に単語頻度、文書頻度、特徴語の稀さなどを総合評価してランキングします(次ページ上図)。
「こんな問題について答えてる自由回答はないかね?」と組織トップに聞かれた時、また、分析官自身が、「こんな仮説思いついたけれど、関連の意見はどれくらいあるだろうか?」などと発想したとき、それらをそのまま入力、コピー&ペーストすると、関連順のランキングが速やかに得られます。
問への答えを含む長めの記事を探したり、それらに、ネガポジ値、回答者プロフィール(属性)、選択肢回答が付いた状態で関連度の高い自由回答をブラウズすることができます。ランキングに浮上した回答文いくつかからコピー&ペーストした長い文章をそのまま問い合わせテキストにして、ピンポイントで、複数のポイントを含む回答が他にないか、探すこともできます。

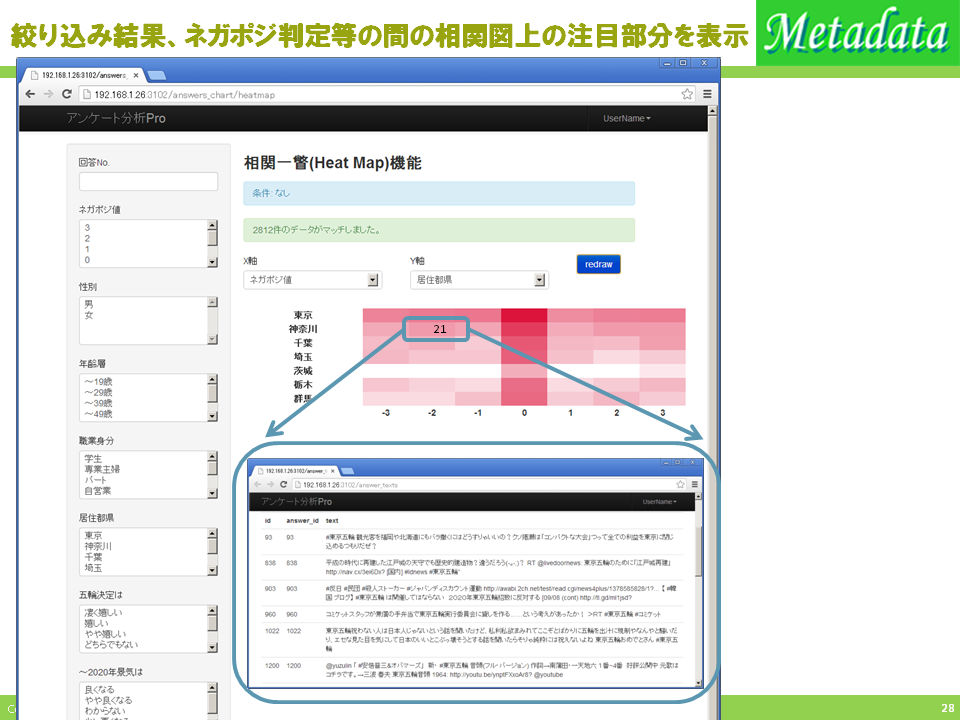
4. ヒートマップによる数値との相関一瞥機能
選択肢やプロフィール、テキストのネガポジ評価値等の間に、特徴的な相関関係がないか、解析します。左図の例では、?3?+3の7段階のネガポジ値と、関東1都6県の回答者の居住都県との相関関係が一目でわかるようになっています。 このモードでは、赤色の濃さは該当する回答者数に比例。特異に多いと思われた、「神奈川県の「?2」」の箱にマウスをかざすと、該当人数21が表示されます。
ヒートマップ上の該当箇所の生データの一覧を呼び出す機能
回答数をマウスクリックすると、該当の回答文全てをポップアップ窓で見ることができます。
データを漫然と見ただけでは判らなかった相関関係を一瞥するだけで見つけられるため、オンラインで何度でも試行錯誤を行なって、次々と仮説や結論を充実させていけます。

5. 追加調査を手軽に行う『ツイ追(ついつい)』機能 (オプション)
上図のアンケート・サンプルは、ツイッターで、ハッシュタグ #東京五輪 を含み、東京開催決定が発表された9月8日前後1カ月間のツイート数千件を集めて自由回答としたものです。仮属性として年齢、性別、居住地を、書き込みと矛盾しない程度に付与し、さらに、学生アルバイトにより2種の選択肢回答「東京五輪決定は嬉しいか」「2020年に向けて景気はよくなるか悪くなるか」を追加しました。
ツイート、特にハッシュタグ付きのツイートは、特定の話題についての意見表明を集めやすく、賛否・中立の違いなども鮮明に出る傾向があります。このため、あたかも元からアンケートで収集した自由回答のように見えるツイート群が大半を占めることも少なくありません。
一方、大きな時間コスト、金銭コストをかけて、社員や回答者の時間という稀少資源を使うアンケートは、設問の不足や不備に気付いても、そう気軽に追加実施することはできません。そこで、『ツイ追(ついつい)』機能を提供いたします。アンケート分析Proを使って、アンケート結果と対話して得られた仮説、暫定の結論を検証するために、ツイッターの「高度な検索式」を生成し、調整の上、過去長期間にもわたるツイートHTMLファイルをダウンロード。それを投入すると、アンケート追加分として、自由回答を中心に補ってデータベースを充実させ、その上で、上記の各種分析機能が使えるようになります。
6. 用語解説
高精度ネガポジAPI
7段階のネガポジ属性(excellent, very good, good, neutral, no good, bad, very bad) を日本語の形容表現99%以上に付与。「物価が?高い:-2」「背が?高い:+1」のように多数のフレーズ辞書と、文脈を反映した(否定、二重否定、逆接、仮定節等に応じて適切に積算)ロジックを備え、段違いに高い精度を誇ります。
ヒートマップ
ヒートマップは、もともとは2次元平面で温度の高低を色の違いで表現した温度分布図を意味。ネットマーケティング分野では、Webページ上での閲覧者の視線分布、または広告などのクリック率の分布をカラー表示した図に限定されていたが、アンケート分析Proでは汎用的に、2軸を選んでその間の相関関係を直感的に把握し、選んだ個所をドリルダウン表示する「見える化」ならびにドリルダウン操作のGUIとして採用した。
他のAPI
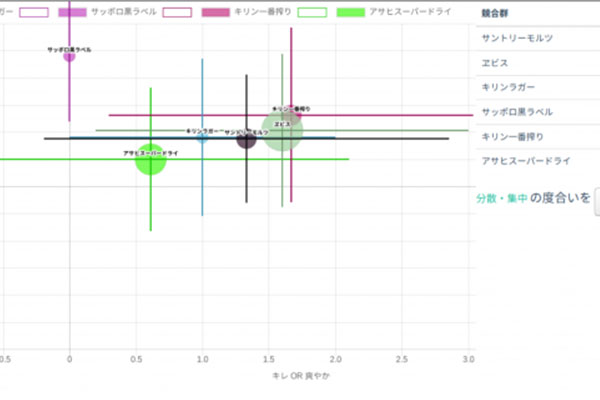
あらゆる自然テキストデータを自動分類し、ポジショニングマップを自動で作成します。
2枚の人物(など)の画像がどの猫にどれだけ似ているかのランクや数値から、猫同士の相性に紐づけて画像の人間の相性を一瞬で判定します。

無料でお試しいただけます! AI冗長出力オーガナイザのお試しはこちらから AI冗長出力オーガナイザとは? AI冗長出力オーガナイザは、ChatGPT、Bing、Bardなどの文章生成AIに多量に出力させた結果を統合・整理 […]
シンプル機能の企業向けソーシャルメディア投稿管理アプリです。

金曜VoC分析講習会開催中 New! 意味抽出と人工知能による自動分類機能が仮説の発見と検証のパワーを数100倍に強化するVoC分析AIサーバ。これを駆使して、画期的なフリーテキスト、フリー・アンサーの分析を体感する […]

こちらのサービスは現在、人工知能搭載テキストマイニングシステムAIポジショニングマップとして、お客様ご自身でセルフサービス分析を行っていただけるよう提供しております。 ポジションマッパーとは ポジションマ […]
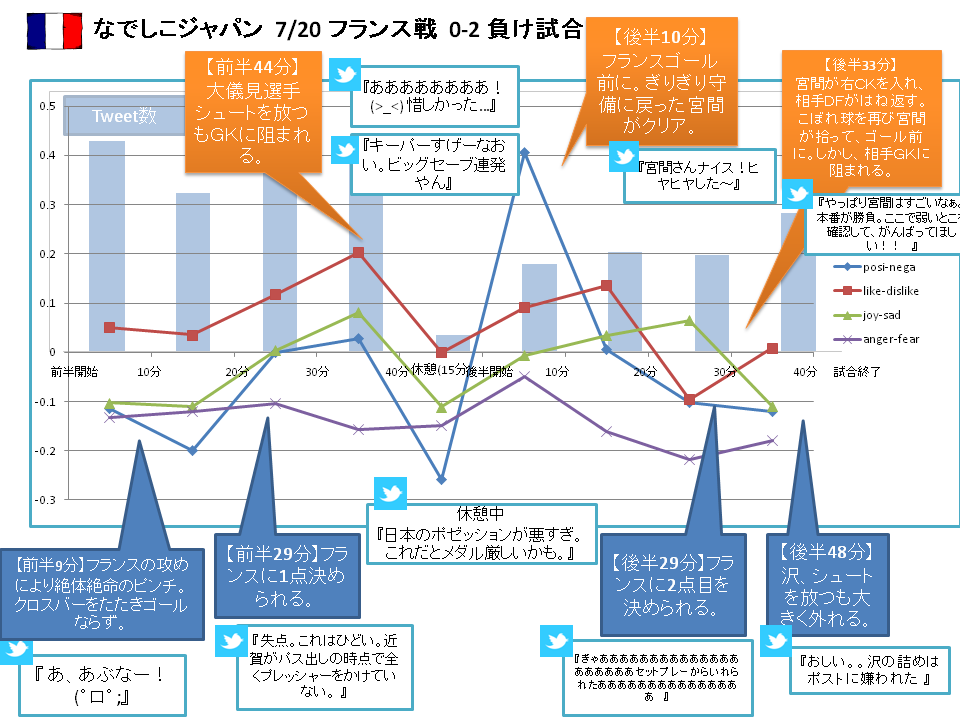
ブランドや商品の評判・印象を、各々に適した評価軸・分類軸で分析します。
アンケート分析Proのご紹介 数値との相関一瞥機能や、追加調査を手軽に行う「ツイ追」機能を装備し、ハイエンドの分析官のひらめきを支援 1. 背景 ビッグデータの時代といわれ、大量のデータ、顧客の声、ソーシャルメディアの書 […]

★こんなお困りごとにFaceSafe99 ■Facebook、ツイッターでマーケティング、広報したいけれどいつ何が書かれるかわからずリスクが怖い ■極端な攻撃などは、365日24時間リアルタイムでブロックして欲しいがコス […]
専門画像認識のための学習済ディープラーニング・システムをご提供します。

2つのグループに様々な要素・存在が多数いるときに、最適なマッチングをご提供するソフトウェアです。

Webサイトに受付嬢を置き、わかりやすく商品を紹介できます。
欲しい検索ワードのツイートの全数取得をサポートをいたします。