xTech

Fintech・マーケティング・人材マッチング向けの超高速多対多マッチングエンジン「xTech」のご紹介
※2021.11 xTech for TV CM発売!
ソフトウェアの詳細はこちらへ!
「xTech」(エックステック)とは、2つのグループに様々な要素が多数あるときに、その最適な組み合わせを、全体として多数生み出すソフトウェアです。
・人材と企業、プロジェクトのマッチング
・シフト勤務や放映枠などの時間枠とコンテンツのマッチング
・過去の多彩な実績案件に似た新案件を多数発掘するBtoBマーケティング
・購買実績に基づいて有望な見込み客を多数発見するBtoCマーケティング
・メールマーケティング、ソーシャルマーケティング
上記の分野にて既に効果が実証されています。
また、
・人材と会社や事業、融資成功事例と失敗事例、
・過去の多数の融資事例群との類似性から最適な融資対象案件群を見つけ出す自動融資AI
などのいわゆるFintechの分野に応用することができます。
その他にも具体的に、
・不動産などのオンリーワン商品と顧客、人事情報による適材適所の再配置、
・大規模ECサイトの商品などの有限リソースの顧客への最適な割り当て
などの活用にも期待ができます。
■「xTech」技術の特長
従来、加速度的に増していた計算時間を、解答として出力する組み合わせ数に比例する時間に抑え込むことに成功!
つまり、
参加者数が10万の単位になってくると、数万倍から数10万倍も高速となり、事実上不可能だった応用が可能
となります。
業務時間中に、何度でも評価、シミュレーションをやり直せることで、マーケティングや、人事・人材活用分野、そして金融テクノロジーはじめ、諸分野(x)をTechnologyにより自動化し、最適化を強力に推進します!
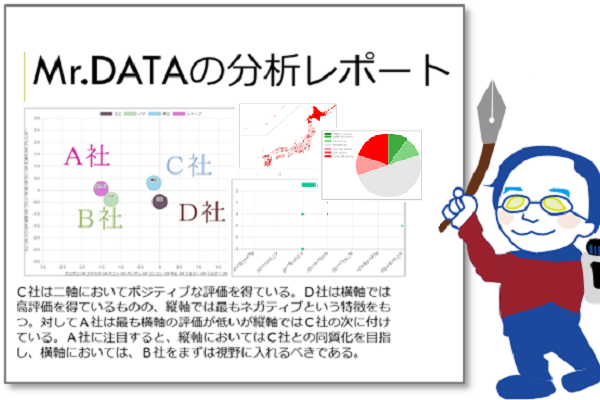
■「xTech」はディープラーニングとどう違うのでしょう?
ビッグデータが溢れ、その活用のための分析が人手では追い付かず、人工知能的なソフトウェアを業務に組み込む問題意識が高まっています。
特にディープラーニングが注目を浴びていますが、下記のような欠点があります。

これらの改善と平行して、明確なモデル、数学的な性質が解明済のアルゴリズムで、結果を予測、シミュレーションできる高速な問題解決手法が求められ始めました。
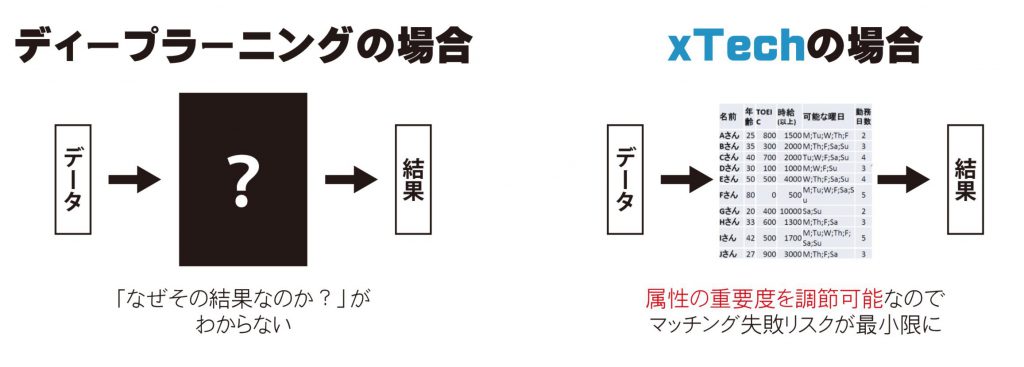
■「xTech」は従来の多対多の組み合わせ最適化とどう違うのでしょう?
上記のようなディープラーニングの欠点を解決可能な手法(数学的な性質が解明済のアルゴリズム)としては、従来から、2グループ間の最適、最大数のマッチングを行うアルゴリズムが知られていました。
メタデータ株式会社の多対多のマッチングエンジンxTechも、従来の多対多マッチングエンジンと同様、機械学習に特有の上記問題点を解決しています。
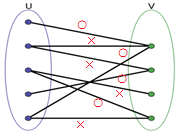
その動きを、図で説明します。×のついた線は絶対的な制約に違反する、失格の組み合わせです。
これら×の黒線を棄てた上で、組み合わせが獲得するスコアが特に高いものが、○のついた線として残ります。この○のついた線のスコアの合計が最大になるように計算していきます。
従来の全体最適化の計算方法との違いを一言でいえば、超高速な点です!上図の点や線の数が10万位になると、4,5桁、すなわち、数万倍から数10万倍速く、計算を完了します。そして、多くの場合に、両者の結果は殆ど一致しています。
マッチング結果を視覚化したこちらをご覧ください。
このページでは、従来法と左右に並べてマッチング結果を比較しています。各左側、右側のメンバーをマウスでつまむと、その相手がどのようになっているかを拡大表示し、上下に動かしながら快適に閲覧することができます。
■「xTech」は多種多様な人々の属性などをちゃんと適切に扱ってくれるのですか?
マッチングの度合い、スコアの評価には、両側参加者の属性を、様々なデータ型(集合型、整数型、浮動小数点型、日付時刻型・・・)に合わせてベクトル数値化し、相性の総合指数を瞬時に算出できるようにしています。
マーケティング目的の初期案件では、50種類以上の属性を備えた高実績ユーザ群と類似した多彩なユーザを、10倍以上の人数を発見するエンジンとして活用しています。これにより、数百万人の中から数千人の優良ターゲット、有望な潜在顧客をいくつかの異なる条件の下で発見する計算処理が、翌朝の営業開始までに完了するようになっています。
■「xTech」の超高速性能の実験結果
実際に、xTech多対多マッチングエンジンで、マッチング成立数を2万、4万、6万、8万、10万と増やしていった際に、計算時間が、約1.3秒から約6.5秒となった結果を左下グラフに示します。右に置いた比較実験結果は、従来アルゴリズムで、参加者数を100から1000まで増やしたときに処理時間がほぼ一から、700秒にまで急増。万の単位では全く実用にならないことを示しています。10万の水準となると、6.5秒 vs 2週間という5桁以上の速度差となりました。 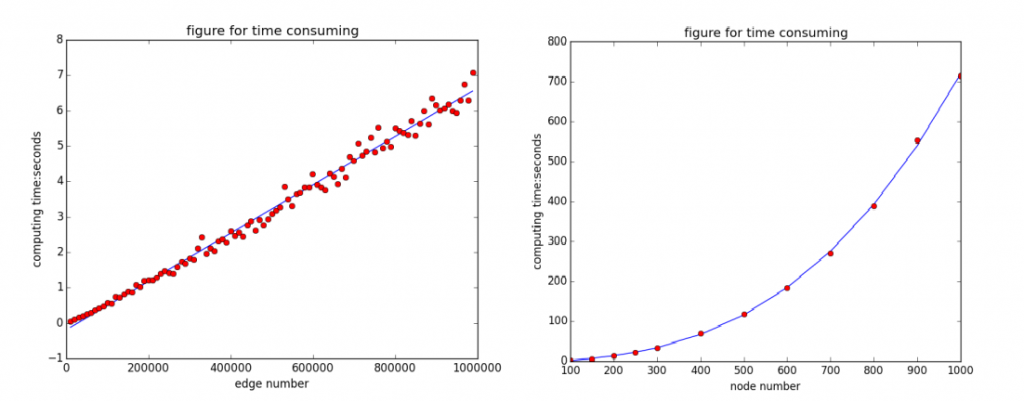
図 xTechの超高速性 成約(約定)数に比例 VS オープンソースの従来アルゴリズムで計算
■ 応用用途、利用シーンについて
もともと、多対多のマッチングアルゴリズムは、数理工学、グラフ理論の教科書で「(集団)お見合いアルゴリズム」と呼ばれ、往年のTV番組、フィーリング・カップル5対5のような事例で、男女間の最適なマッチングをなるべく多く、一遍に求めることで知られていました。同質な、または異質な2グループの間で、様々な属性(男女なら年齢、身長、年収、学歴、趣味、勤務地、等等)の間の制約条件や相性さえ定義できれば、どんな分野のテーマ、問題解決にも適用することができます。
〇 Fintech分野
過去の多種多様な融資成功案件(あるいは失敗案件)の属性と、新規案件の属性をマッチングさせ、「最近私が直接扱ったいくつかの案件とは似ていないが、過去、先輩が成功させた案件10万件のうちのあれとそっくりなので成功確率は高い」という機械知能ならでは大規模な比較計算が可能です。
〇 EC分野 - Marketech
同じ商品でも、有限の在庫をもち、売買条件や相性(消費者の好み)の異なるショップと買い手をマッチングさせたり、キャンペーンの対象者を決めたりすることへの応用が考えられます。満足度評価のアンケート実施の際に、有為な回答が期待できる、なるべく多彩な顧客群を選び出すことにも使えます。
〇 人事AIの分野 – HRTech
人と仕事のマッチングの最適化で、よりよい組み合わせを客観的、科学的に計算し、人間による最終判断のための最重要データとすることができます。また、「なぜうちの会社には求職者が多く集まらないのだろう?」と問い合わせてきた会社に対しては、「それでは、御社だけ時給を50円上げてみて、紹介数や質がどう変化するかシミュレーションしてみましょう」とご提案いただくことができます。
これにより、低コストでごく短時間に、人材紹介のコア業務である人材マッチングを仮条件でやり直してみたり、といったサービスが提供出来るようになります。
この他、何10もの業界で、多種多彩な組み合わせ最適化を行うことができます。
お気軽にお問合せください
他のサービス