Mrテキスト分析
こんなお悩みありませんか?
クチコミや商品レビューや、行動欄・メモ欄・上司意見などのある日報や週報、また、複数の自由回答欄がある社内外の様々なアンケート回答などの分析、利活用でお困りではありませんか? せっかくの貴重なテキスト情報が宝の持ち腐れになっていたりはしないでしょうか? あるいは、FAQが大規模になり、ひいてはそのFAQをもとに作ったチャットボットのスキル(シナリオ)の改善、拡充、メンテナンスが大変になったりしていないでしょうか?
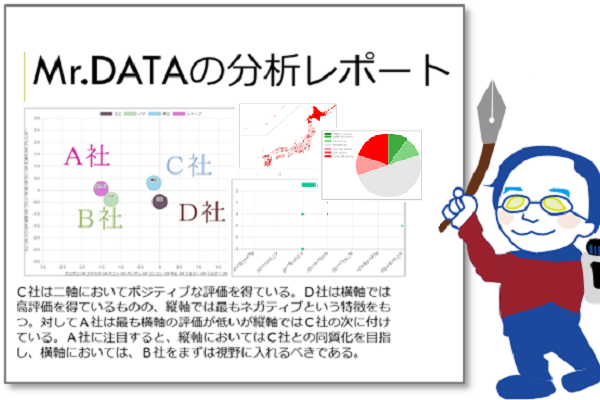
今回の新製品、”Mrテキスト分析” は、複数の自由テキスト欄に対応し、異なる回答欄の間に埋もれた意味的な結びつきをも、色付きでヴィジュアルに浮かび上がらせます。一種の、XAI=eXplainable AI「説明可能なAI」です。例えば、下図の講演受講者アンケートでは、講演者「野村」「松田」「小山」への、S,A,B,C,D 5段階評価と共に各々自由コメントがあります。内容に踏み込んで書かれたコメント、「テキスト分析が興味深く、分かり易く、とても面白い講演だった」というのに近い内容のものを、3人への自由コメントすべてに対して探します。単語の重なり具合を精妙な重み付けで判定する度合いを40%、意味の重なり具合で判定する度合いを60%で判定させた結果が下記の画面です。
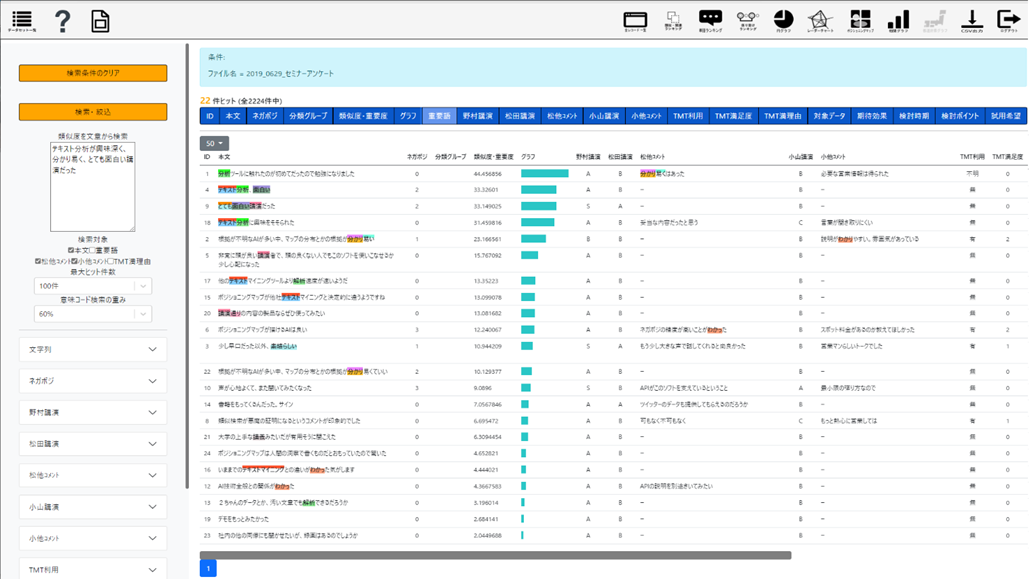
総合類似度が、横倒しの青い棒グラフであらわされ、3つの自由コメント欄で、類似の根拠となった個所に色がついています。単語の重なりが上側、意味の重なりが下側で、別の色が付いたツートンカラーになっています。このようにして、複数のテキスト欄にまたがる共通性を素早く認識し、たとえ数千人、数万人分のアンケート回答があっても異なる設問にまたがる関係性、別の個所に書かれた根拠などを見逃さず、秒単位、分単位で迅速に見つけることができます。
FAQ、チャットボットについては、質問中の重要キーワード、あるいはその類義語、関連語をきちんと含んだ回答文になっているかのチェックが、色付きで即座に出来ます。ある回答文全体との類似度で質問文を類似ランキングで並べたときに、質問と回答の対応が撚れているのを見つけることもできます。あるタイプの質問には丁寧に回答文が用意されているのに、同様の詳細で丁寧な回答が別の質問には用意されていない状況を浮き彫りにすることもできます。
ボットのログに、「すみません、ご質問の意味が分かりませんでした」「回答が見つかりませんでした」などのエラーがあったのを改善したいとします。該当の質問文と、他の質問文や回答文全部の類似ランキングの上位に、色付き個所が違う回答Aと回答Bが見つかります。各々単独では、その質問にマッチする回答として十分ではありませんが、この2つをつないだら回答として成立するのではないでしょうか。「あー、この回答Aと回答Bの前半と後半をつないだ回答を用意しておけばその種の質問にも答えられるようになる!」とすぐに思いつき、チャットボットの回答率を向上させ、ひいては、受注や好印象を獲得出来るようになります。
Mrテキスト分析でできること
・複数の自由テキスト欄に対応
新製品“Mrテキスト分析”では、アンケートの問1~問9の各々に「その他」(括弧内に記述)として、自由回答を記述した回答など、複数のテキスト欄をもつCSVファイルを読み込んで、意味解析を行い、関連・類似ランキング等を行うことができます。これにより、各設問間の隠れた相関関係を見出して、より広く、深い分析を行うことができます。アンケート以外では、例えば、営業日報の「行動」欄、「予定」欄、「上司コメント」欄の間の関係を辿ることができます。
・関係図と係り受けランキング
“Mrテキスト分析”では、表形式の係り受け(主語-述語や目的語-述語などの関係)の頻度ランキングに加え、そのサマリーを見える化することにより、複数の話題、トピックの連鎖から、話題のトレンドを把握できるようになりました。
・ワードクラウドと単語ランキング
“Mrテキスト分析”では、表形式の単語出現回数のランキングのサマリーとして、様々な絞り込み条件に対応したワードクラウドを表示することで、データセットの様々なサブセットの重要語の分布を一望にすることができます。
・データ型と複数値
日付時刻、整数値などで範囲指定による絞り込みができるようになった他、文字列セミコロン「;」等で区切られた複数値の欄をもつデータについて、適切に検索・絞り込みができます。
Mrテキスト分析で新たにご提供する付加価値 ~直観的な分析も!
この他、“AIポジショニングマップMrDATA”の機能について、経営者のためのポジショニングマップ描画などに加え、次の強化を行っています
・30数万語彙に増強され詳細化された意味カテゴリを活用した類似検索と意味による自動分類
・自在な組み合わせで加工結果のCSVを出力
・レーダーチャートなどの新しい「見える化」の提供
係り受けランキングの可視化
共起ネットワークによって係り受けランキングを可視化しました。
係り受けランキングだけではどうしても上位の単語に注目してしまいがちでしたが、可視化されたことで頻度が中程度の単語でも一画面で確認できるようになりました。

単語の係り受けを可視化したことで、係り受けをより多くされる単語やそうでない単語を一目で確認できるようになりました。
表現力の増したポジショニングマップで新たな仮説の発見や定量評価が可能
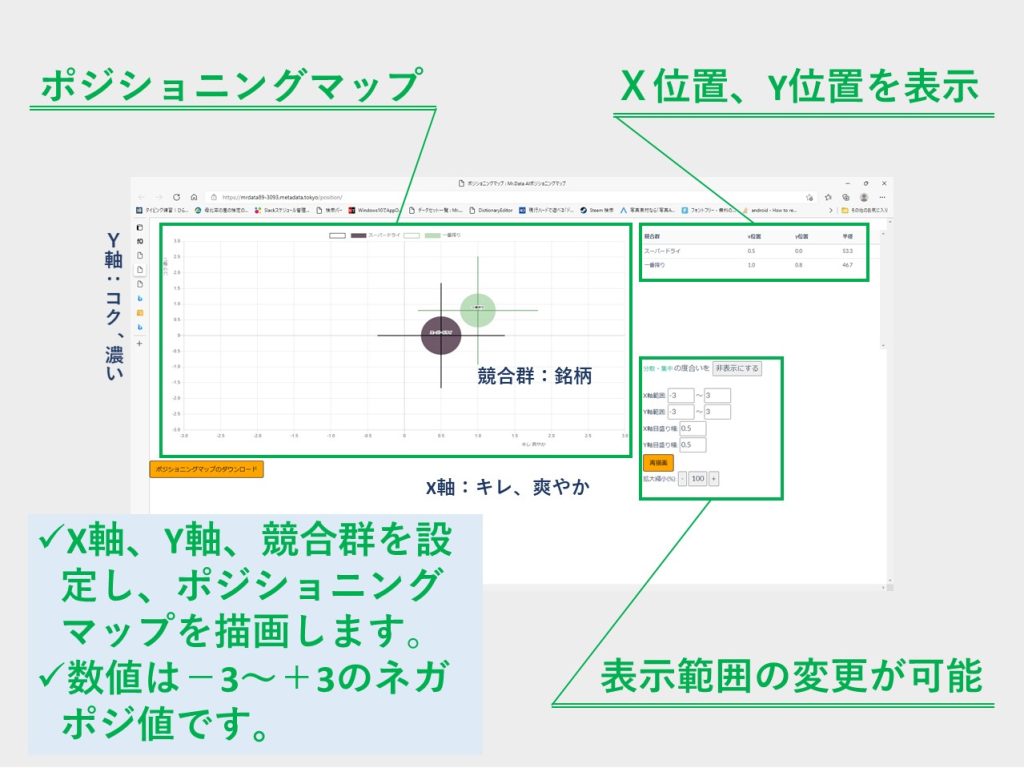
X軸、Y軸、競合群を自由に設定して様々な相関を分析できます。テキストデータを眺めているだけでは気付かなかった新仮説や知識を発見できます。
一目瞭然の経営指針が得られる
競合間のポジショニングマップを描くことで一目瞭然の経営指針を得られます。
5万通りの分析が可能
法人の属性、個人の属性など、文字通り5万とあります。これらが皆、ポジショニングマップのX軸、Y軸の分析軸の候補になります。
人間と機械の得意技を合わせてポジショニングマップを描く
人間ならではの常識、因果関係の判断を交えて読み解きます。
当社サービス6つの「高」
メタデータ株式会社では、設立当初より、ビッグデータの時代にいわゆる「情報爆発」の救い主となるのが “メタデータ” であると提唱してまいりました。詳細は、こちら日本データマネジメントコンソーシアムの記事をご覧ください。
当社サービスの特長は、次の6つの “高” にまとめられます:

6つの高についてこちらのページで詳しくご説明しています。
他のサービス